- sales@hot-mining.com +86 28 8331 1885 +86 15196677188
-

-

-

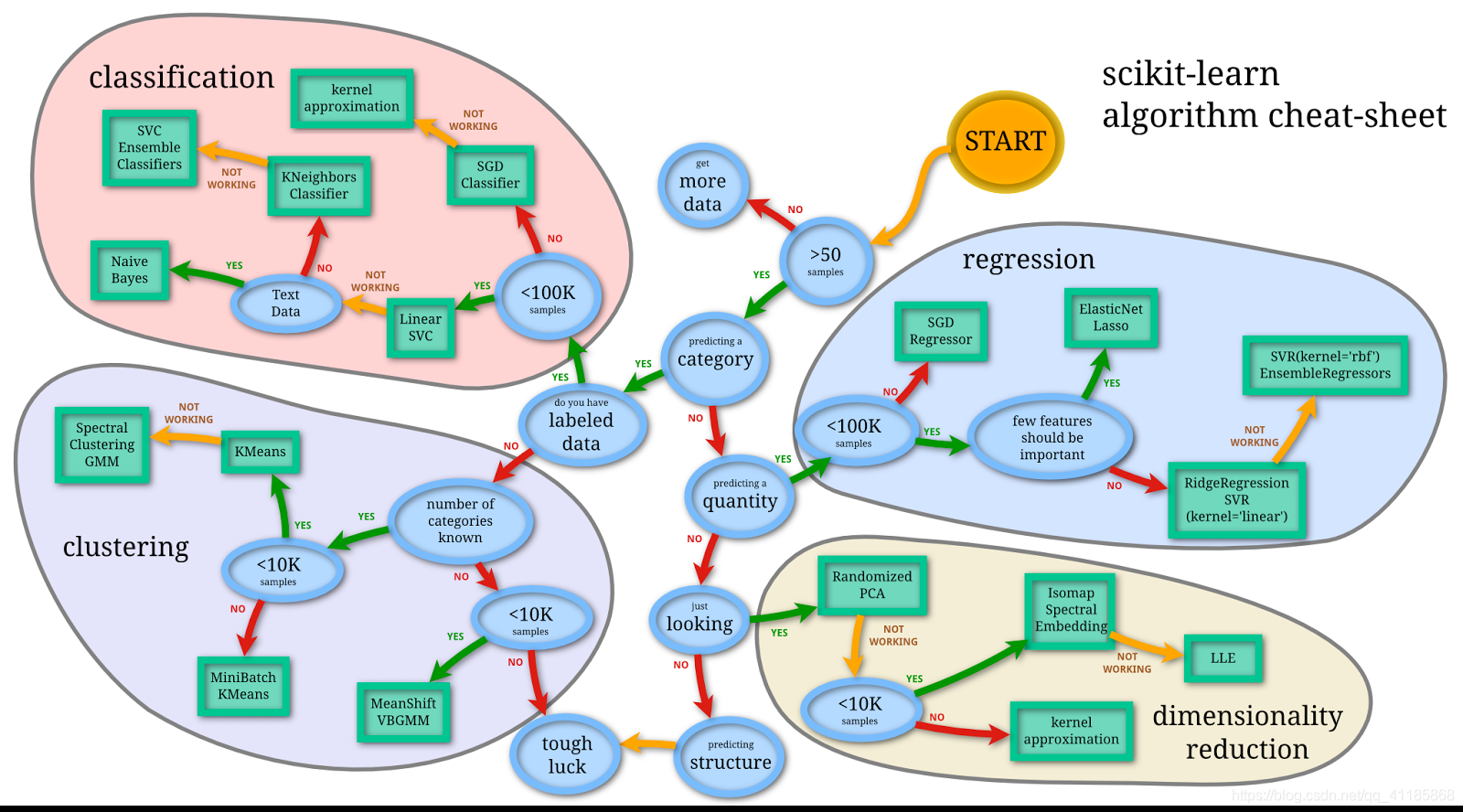
Machine learning can be used to solve a wide range of problems. However, there are many different algorithms, and knowing which algorithm is suitable for a particular application scenario can be complicated. This article focuses on choosing the most suitable machine learning algorithm when applying artificial intelligence to the mining industry.
1. Determine the problem you want to solve
The first step is determining the problem you want to solve: is it a dimensionality reduction, prediction, classification, or clustering problem? This can narrow the selection range and determine which type of algorithm to choose.
What type of problem do you want to solve?
Classification Problems: logistic regression, decision tree classifier, random forest classifier, support vector machine (SVM), naive Bayes, or neural network
Main Applications: mineral pre-sorting (e.g., XRT), mineral grade and element detection (XRF-X-ray fluorescence slurry grade detection, X-ray ash analyzer), intelligent flotation, predictive maintenance.
Clustering Problem: k-means clustering, hierarchical clustering, or DBSCAN
Main applications: before building supervised machine learning algorithms for classification and prediction applications, unsupervised machine learning is needed to analyze a large amount of raw data, achieve clustering analysis of data, and find relationships and hidden features between different categories of data.
For example, before building a model for the dynamic density control system in a coal preparation plant, it is necessary to find the relationships between various data (such as the relationship between valve opening and separation density, the relationship between valve openings, etc.). The three most essential variables in the dense medium coal preparation process are the density of the dense medium suspension, the coal slurry content, and the qualified medium bucket liquid level. HOT has researched data feedback, parameter setting, and dense medium density control in the dense medium coal preparation process and established a model for predicting the density of the dense medium suspension. In this process, HOT used the least squares support vector machine (LS-SVM) algorithm to train sample data, establish a calibration model, and accurately calibrate data detected in the online gray measurement instrument.
2. Consider the size and nature of the dataset
a) Size of the dataset
If the dataset is small, choose a less complex model, such as linear regression (for data analysis with less than 100 samples, Excel can perform good linear regression analysis of multiple variables, including binary variables). More complex models, such as random forests or deep learning, may be appropriate for larger datasets.
How to judge the size of the dataset:
Large datasets (thousands to millions of rows): gradient boosting, support vector machine, neural network, or deep learning algorithms.
Small datasets (less than 1000 rows): logistic regression, random forest, decision tree, or naive Bayes.
For mining and coal preparation plants, the data is usually extensive. For example, the dynamic density control system may have thousands of data lines for just a few teams, such as ash content, density, valve opening, etc., which is only one production link in the entire coal preparation process. Especially for large and medium-sized mining group companies with multiple mining and coal preparation plants, cleaning, analyzing, and applying massive data is very challenging. For example, Shendong Coal Group's Shanwan Intelligent Coal Preparation Plant has established a customized, precise production development and application model (as shown in the figure below), which is connected to Shendong's ERP and business execution system data to obtain production plans, loading plans, coal quality data, etc. Hand-entered data, receive real-time data from the automation system, analyze and store data in real-time, and display statistical data from the production site to the management in an accurate and timely. This model can predict the product quality under different production methods based on the raw coal quality information, combined with the cost accounting method, and perform statistical analysis on the product cost and benefits under other production methods in related systems, to analyze the optimal production method combination based on the principle of maximizing benefits and provide support for management and decision-making.

b) Data labeling
Data can be labeled or unlabeled. Labeled data can be used in supervised machine-learning models like random forest, logistic regression, or naive Bayes. Unlabeled data requires unsupervised machine learning models, such as k-means or principal component analysis (PCA).
c) Feature properties
For categorical features, decision trees or naive Bayes may be used, while for numerical features, linear regression or support vector machines may be more appropriate.
Categorical features: decision trees, random forest, naive Bayes.
Numerical features: linear regression, logistic regression, support vector machines, neural networks, k-means clustering.
Mixed features: decision trees, random forest, support vector machines, neural networks.
d) Missing values
Decision trees, random forest, or k-means clustering may be used for datasets with many missing values, and for datasets with missing values that do not fit these models, linear regression, logistic regression, support vector machines, or neural networks may be considered.
3. Interpretability vs. Accuracy
Some machine learning models are more accessible to interpret than others. If interpretability is important, models such as decision trees or logistic regression can be selected. If accuracy is the key concern, more complex models such as random forest or deep learning may be more suitable.
4. Data complexity
If there may be non-linear relationships between variables, more complex models such as neural networks or support vector machines may be needed.
Low complexity: linear regression, logistic regression.
Medium complexity: decision trees, random forest, naive Bayes.
High complexity: neural networks, support vector machines.
In the mining industry, most data falls into the medium to low complexity range, with only a few intelligent mining processes using more complex algorithms. For example, in a coal preparation plant's dynamic density control system, a data mining model was established using neural network, logistic regression, and decision tree algorithms to predict the circulating medium density, with input matrices including belt weighing, ash analyzer, and circulating medium density. After comprehensive comparison and evaluation using ROC curves and confusion matrices, the neural network algorithm was more suitable for predicting the circulating medium density. In addition, BP neural networks are also used in flotation and mineral processing plant reagent addition systems.
5. Balancing Speed and Accuracy
When considering the trade-off between speed and accuracy, more complex models may be slower but could also offer higher precision.
Speed is more critical: decision tree, naive Bayes, logistic regression, and k-means clustering.
Accuracy is critical: neural networks, random forests, and support vector machines.
6. High-dimensional Data and Noise
If dealing with high-dimensional or noisy data, dimensionality reduction techniques (such as PCA) or models that can handle noise (such as KNN or decision trees) may be needed.
Low noise: linear regression, logistic regression.
Moderate noise: decision tree, random forests, k-means clustering.
High noise: neural networks, support vector machines.
7. Real-time Prediction
If the real-time prediction is needed, models such as decision trees or support vector machines should be selected.
For example, XRT Ore Sorting, XRF slurry grade detection, and predictive analytics;
8. Handling Outliers
If the data has many outliers, robust models like support vector machines or random forests can be chosen.
Models sensitive to outliers: linear regression, logistic regression, power regression.
Models with high robustness: decision tree, random forests, support vector machines.
9. Deployment Difficulty
The ultimate goal of a model is to be deployed, so deployment difficulty is the last factor to consider:
Some simple models like linear regression, support vector machines and decision trees can be relatively easily deployed in production environments because they have small model sizes, low complexity, and low computational costs. However, on complex datasets such as large scale, high dimensionality, and nonlinearity, the performance of these models may be limited, and more advanced models, such as neural networks, are needed.
For example, the XRT Ore Sorting technology algorithm mainly uses basic algorithms such as random forests and support vector machines for mineral and gangue (coal and waste rock) identification and analysis rather than convolutional neural networks. This is because, in XRT's actual production application, precise separation of minerals at the sub-millisecond level is required. Therefore, more advanced algorithms cannot meet the practical needs of production.
In conclusion, choosing the correct machine learning algorithm is challenging and requires balancing specific problems, data, speed, interpretability, deployment, and selecting the most suitable algorithm according to requirements. However, following these guiding principles ensures that your machine learning algorithm is highly suited to your specific use case and provides the necessary insights and predictions.
Contact us
Email: sales@hot-mining.com
Linkedin: Click here
